

DFS(Depth-First-Search)란?
그래프의 시작 노드에서 출발하여 탐색할 한 쪽 분기를 정해서 최대깊이까지 탐색을 마친 후, 다른쪽 분기로 이동하여 다시 탐색을 수행하는 알고리즘이다.
또한 DFS는 그래프 완전 탐색(모든 노드를 방문)이며, 주로 스택(Stack) 자료구조를 사용하거나 재귀 호출을 통해 구현된다.
DFS 장점과 단점
| DFS 장점 | 현 경로상의 노드들만 기억하면 되므로 저장공간 수요가 비교적 적음 |
| 목표 노드가 깊은 단계에 있을 경우 해를 빨리 구할 수 있음 | |
| DFS 단점 | 해가 없는 경로가 깊을 경우 탐색시간이 오래 걸릴 수 있음 |
| 얻어진 해가 최단 경로가 된다는 보장이 없음 |
그래프 표현 방법
우선 탐색하기 전 연결의 정보인 그래프를 표현부터 해야할 것이다. 그래프를 표현하는 방법에는 인접 행렬과, 인접 리스트 두 가지 방법으로 표현할 수 있다. 결론부터 말하자면 인접 행렬은 직관성이 좋지만 메모리 차원에서 인접 리스트가 더 좋아서 보통 인접 리스트를 많이 사용한다.
그래프 표현 방법 1 - 인접 행렬(Adjacency Matrix)
인접 행렬은 행렬로 정점(Vertex)들 사이의 관계를 표현하는 것이다. 인접 행렬에서도 방향 그래프인지 무방향 그래프인지에 따라 표현하는 방법이 다르다. 아래의 그림을 보면 알 수 있듯이 간선 방향의 존재 유무에 따라 행렬의 값이 변한다.
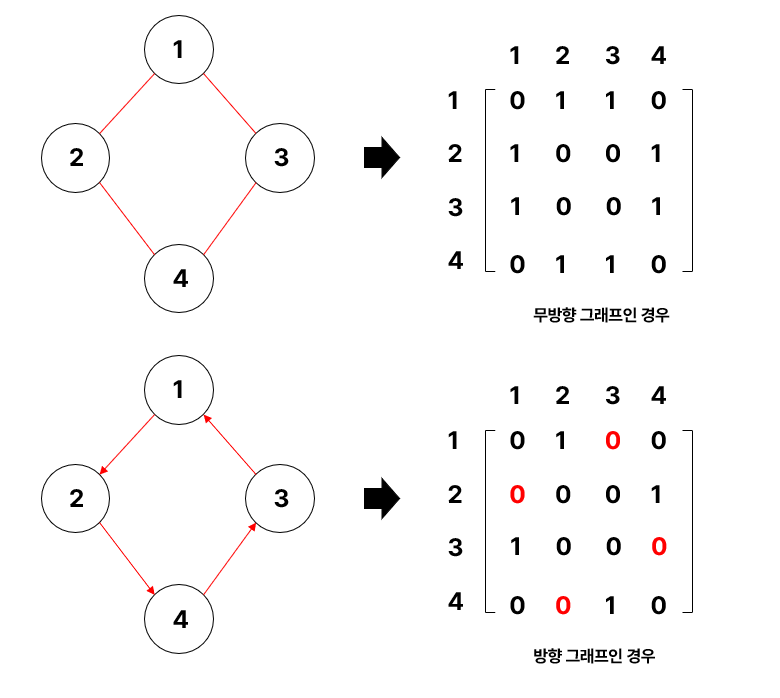
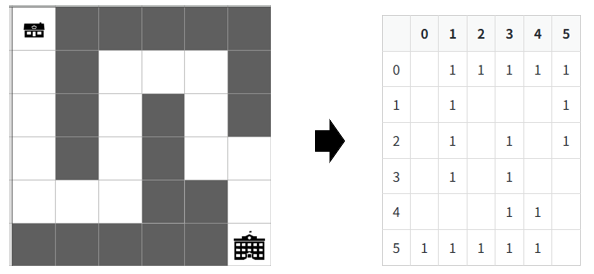
만약 집에서부터 학교까지의 지도가 있을 때 길은 0으로 벽은 1로 표현하면 이 지도를 인접 행렬로 아래의 그림과 같이 표현할 수 있다.
그래프 표현 방법 2 - 인접 리스트(Adjacency List)
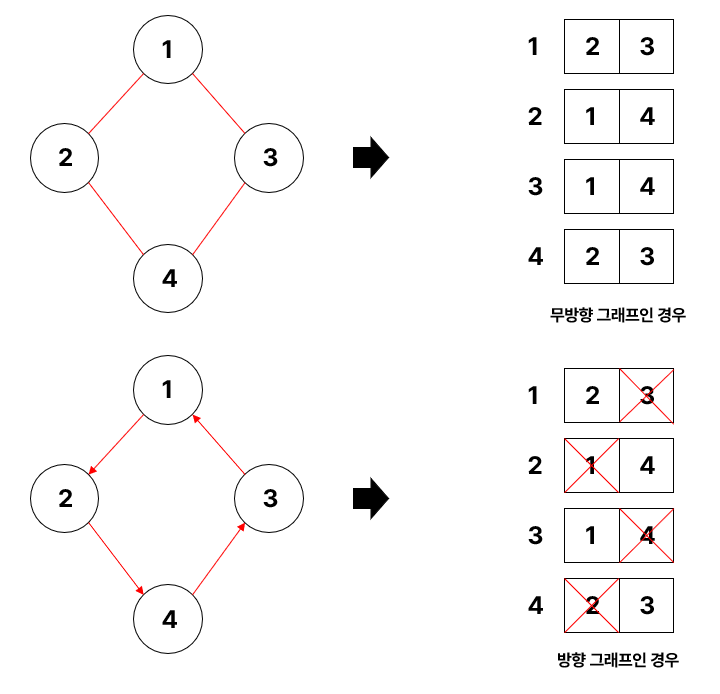
인접 리스트는 리스트에 각 정점(Vertax)이 연결된 노드들의 정보를 저장하는 방법이다. 인접 리스트 또한 방향 그래프인지 무방향 그래프인지에 따라 표현하는 방법이 다르다. 아래의 그림을 보면 해당 정점에 연결된 노드의 정보를 리스트 형태로 저장하는 것을 확인할 수 있다.
DFS 핵심 이론
1) 방문 여부 확인용 배열(visited)
DFS는 한번 방문한 노드를 다시 방문하면 안되므로 노드 방문 여부를 체크할 배열이 필요하다. 예를들어 1~6의 노드를 가진 그래프가 있으면, boolean[] visited = new boolean[7]; 으로 배열을 만들어주고 해당 노드를 방문하면 해당 인덱스의 값을 TRUE로 바꿔준다.
노드의 개수는 6인데 배열의 크기를 +1인 7로 해준 이유는 0번 인덱스를 1번 노드로 표현하고 1번 인덱스를 2번 노드로 표현하면 헷갈리니 1번 인덱스가 1번 노드를 표현할 수 있도록 해준것이다. (0번 인덱스는 사용하지 않는다.)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| F | T | F | F | F | F | F |
2) 원본 그래프 -> 자료구조 초기화(인접리스트)
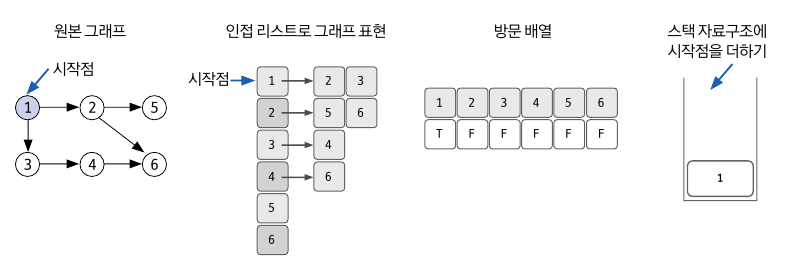
- 시작할 노드를 정한다.
- 각 노드에서 갈수있는 다른 노드를 확인 후 인접리스트로 초기화 한다.
- 시작점을 정했기 때문에 시작점의 방문배열을 True로바꿔주고, 스택에 시작점을 더한다.
3) 스택(재귀함수)에서 꺼낸 노드의 인접노드를 스택에 삽입
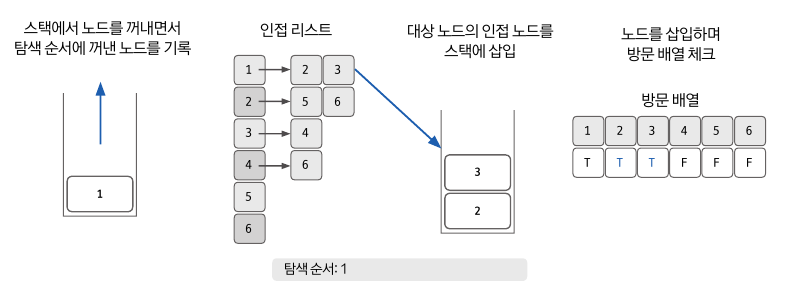
- 맨 처음에 넣었던 시작노드 1을 스택에서 pop 한다. (pop 할때, 해당 값의 방문배열은 T로 변경)
- 1의 인접노드 2,3을 스택에 삽입한다.
- 이 과정을 스택이 비워질 때까지 반복한다.
4) 반복
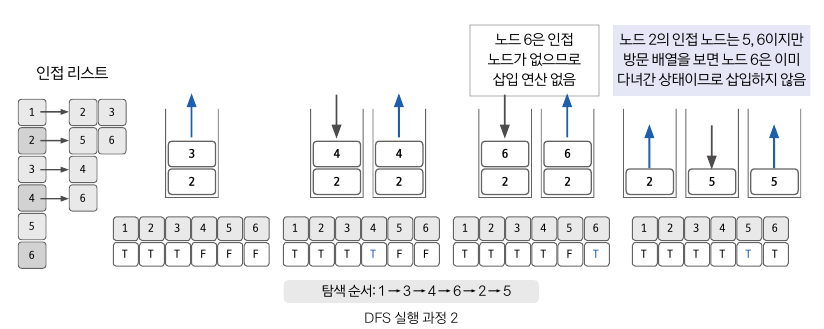
- 위에서 1이 pop되고, 2,3이 스택에 들어있는 상황
- pop(3) -> 3의 방문배열 True -> 3의 인접노드 push(4)
- pop(4) -> 4의 방문배열 True -> 4의 인접노드 push(6)
- pop(6) -> 6의 방문배열 True -> 6은 인접노드가 없기 때문에 push할 노드는 없다.
- pop(2) -> 2의 인접노드는 5,6이지만 6의 방문배열은 True 이므로 push(5)만 할수 있다.
- pop(5) -> 5의 방문배열 True
- stack.isEmpty() == true -> 마지막으로 pop(5)를 하고 나니, 스택이 비워졌다. -> 반복 종료
( 편의를 위해 pop() 괄호 안에 값을 넣은 것, 코드는 pop() )
DFS 구현 1 (Stack 이용)
import java.util.ArrayList;
import java.util.Stack;
public class DFS {
static boolean[] visited = new boolean[7]; //방문 배열
static ArrayList<Integer>[] A = new ArrayList[7];//ArrayList타입 배열
static ArrayList<Integer> procedure = new ArrayList<>(); //탐색 순서 list
public static void main(String[] args) {
//배열의 각 요소마다 ArrayList를 가진다.
for(int i=1;i<=6;i++) {
A[i] = new ArrayList<>();
}
A[1].add(2);
A[1].add(3);
A[2].add(5);
A[2].add(6);
A[3].add(4);
A[4].add(6);
//1번노드에서 DFS 실행
DFS(1); // 같은 클래스 내에서 정의된 static 메서드는 클래스 이름 없이 호출 가능하다.
System.out.println(procedure.toString());
// [1, 3, 4, 6, 2, 5] (스택)
// [1, 2, 6, 5, 3, 4] (재귀)
// 인접리스트에 들어있는 값의 순서에 따라 탐색 순서가 달라질 수 있으나, 두가지 경우 모두 DFS가 맞다.
}
public static void DFS(int v){
Stack<Integer> stack = new Stack<>();
stack.push(v);;
while(!stack.isEmpty()){
int cur = stack.pop();
visited[cur] = true;
procedure.add(cur);
//해당 노드의 인접리스트를 검사하며, visited가 false인 경우에만 stack.push
for (int i : A[cur]) {
if(!visited[i]){
stack.push(i);
}
}
}
}
}
DFS 구현 2 (재귀함수 이용)
import java.util.ArrayList;
public class DFS {
static boolean[] visited = new boolean[7]; //방문 배열
static ArrayList<Integer>[] A = new ArrayList[7];//ArrayList타입 배열
static ArrayList<Integer> procedure = new ArrayList<>(); //탐색 순서 list
public static void main(String[] args) {
//배열의 각 요소마다 ArrayList를 가진다.
for(int i=1;i<=6;i++) {
A[i] = new ArrayList<>();
}
A[1].add(2);
A[1].add(3);
A[2].add(5);
A[2].add(6);
A[3].add(4);
A[4].add(6);
//1번노드에서 DFS 실행
DFS(1); // 같은 클래스 내에서 정의된 static 메서드는 클래스 이름 없이 호출 가능하다.
System.out.println(procedure.toString());
// [1, 3, 4, 6, 2, 5] (스택)
// [1, 2, 6, 5, 3, 4] (재귀)
// 인접리스트에 들어있는 값의 순서에 따라 탐색 순서가 달라질 수 있으나, 두가지 경우 모두 DFS가 맞다.
}
static void DFS(int v){
//방문배열이 true면 return
if(visited[v]) return;
//v 노드에 방문했으므로, 해당 방문배열을 true로 바꿔주고, 탐색순서 리스트에 추가해줌
visited[v] = true;
procedure.add(v);
//해당노드의 ArrayList(인접노드)를 모두 돌며 방문배열이 false인 경우에
for(int i : A[v]){
if(!visited[i]){
DFS(i); //해당 노드에 대해서 DFS를 다시 실행한다.
}
}
}
}
참고자료
[1] 티스토리 ZINU
[2] 티스토리 HS_dev_log
[3] 유튜브 어라운드 허브 슈튜디오
[4] 위키독스 다빈치코딩 알고리즘
'🧠 Computer Science > Algorithm' 카테고리의 다른 글
| [정렬 알고리즘] 삽입 정렬(Insertion Sort) (0) | 2024.12.06 |
|---|---|
| [정렬 알고리즘] 선택 정렬(Selection Sort) (0) | 2024.11.30 |
| [정렬 알고리즘] 버블 정렬(Bubble Sort) (1) | 2024.11.29 |
| [동적 계획법] Kadane’s Algorithm (카데인 알고리즘) (0) | 2024.10.30 |
| Dicision Tree(의사결정나무) (1) | 2024.08.06 |