
개요
배열(Array)은 컴퓨터 과학에서 가장 기본적이고 널리 사용되는 선형 데이터 구조이다. 데이터 구조가 선형이라는 것은 데이터 구조를 구성하는 요소들이 서로 인접해 순차적인 방식으로 정렬되어 있음을 뜻한다.
이 구조는 데이터를 순차적으로 저장하고 접근하는 방식을 제공하며, 많은 알고리즘과 프로그램의 기반이 된다.
배열은 동일한 데이터 타입의 요소들을 연속된 메모리 공간에 저장하는 자료구조이다. 배열의 주요 특징은 다음과 같다.
- 고정된 크기: 배열은 생성 시 크기가 정해지며, 이후 변경이 어렵다.
- 인덱스 기반 접근: 각 요소는 0부터 시작하는 인덱스를 통해 직접 접근할 수 있다.
- 빠른 접근 속도: 인덱스를 통한 요소 접근은 O(1)의 시간 복잡도를 가진다.
- 메모리 효율성: 연속된 메모리 공간을 사용하여 메모리 관리가 효율적이다.
- 다차원 구조 가능: 2차원, 3차원 등의 다차원 배열 구현이 가능하다.
배열의 이러한 특성은 특정 상황에서 큰 장점이 된다. 예를 들어, 데이터의 크기가 미리 알려져 있고 변하지 않는 경우, 또는 빠른 랜덤 접근이 필요한 경우에 배열은 매우 효과적이다. 그러나 배열의 크기를 변경하기 어렵다는 점은 동적인 데이터 처리에 제한이 될 수 있다. 그래서 데이터의 크기가 자주 변하거나, 중간에 요소를 자주 삽입/삭제해야 하는 경우에 리스트 자료구조를 사용한다.
배열은 다양한 알고리즘과 응용 프로그램에서 중요한 역할을 한다. 예를 들어, 배열은 정렬 알고리즘, 행렬 연산, 해시 테이블의 구현 등에 널리 사용된다.
프로그래밍 언어에 따라 배열의 구현과 사용 방법이 다를 수 있다. 예를 들어, C언어에서는 정적 배열과 동적 할당을 통한 배열 사용이 일반적이며, 연결 리스트는 개발자가 직접 구현해야 한다. 반면 Java나 Python과 같은 고수준 언어에서는 동적 배열(ArrayList)과 연결 리스트(LinkedList)를 기본 라이브러리로 제공한다.
배열과 리스트를 효과적으로 사용하기 위해서는 각 구조의 특성을 잘 이해하고, 문제의 요구사항에 맞게 적절한 구조를 선택해야 한다. 예를 들어, 데이터의 크기가 고정되어 있고 빈번한 검색이 필요한 경우에는 배열이 적합할 수 있다. 반면, 데이터의 삽입과 삭제가 빈번하게 일어나는 경우에는 연결 리스트가 더 효율적일 수 있다.
또한, 배열과 리스트는 더 복잡한 자료구조의 기반이 되기도 한다. 예를 들어, 스택과 큐는 배열이나 연결 리스트를 사용하여 구현할 수 있으며, 그래프의 인접 행렬 표현은 2차원 배열을, 인접 리스트 표현은 리스트의 배열을 사용한다.
배열의 선언&초기화
배열이란 "배열은 같은 타입의 여러 변수를 하나의 묶음으로 다루는 것"이다.
변수는 1개의 데이터만 저장할 수 있다. 저장해야 할 데이터의 수가 많아지면 그만큼 많은 변수가 필요하고 아래처럼 코드도 매우 길어진다. 하지만 배열을 사용하면 많은 양의 데이터를 적은 코드로 손쉽게 처리할 수 있다.
int score1 = 83;
int score2 = 90;
int score3 = 87;
int score4 = 75;
배열 선언 후 초기화
int[] score = new int[5];
score[0] = 100;
score[1] = 90;
score[2] = 80;
score[3] = 70;
score[4] = 60;
배열 선언 후 for문으로 초기화
int[] score = new int[5];
for(int i = 0; i < score.length; i++){
score[i] = i * 10;
}
배열 선언과 동시에 초기화
int[] score = new int[]{100, 90, 80, 70, 60};
//선언과 동시에 값을 초기화할 때는 new int[] 부분을 생략할 수도 있다.
int[] score2 = {100, 90, 80, 70, 60};
배열의 길이
배열은 한번 생성하면 길이를 변경할 수 없다.
그 이유는 예를 들어 int[] arr = new int[5]; 라고 하면 하나의 요소가 4byte를 차지하니 총 20byte이다. 이럴 경우 배열은 연속적이기 때문에 메모리에서 20byte인 연속적인 메모리 공간을 확보해야한다. 하지만 int[] arr = new int[10]로 변경하고 싶다면 총 연속적인 40byte인 메모리 공간이 필요하다. 이때, 처음에 연속적인 20byte 메모리 공간 뒤가 비어있다는 보장이 없다. 그래서 변경할 수 없는것이다.
공간이 부족하다면 새로운 더 큰 공간을 만들고 기존의 배열의 요소들을 복사해야한다. 배열의 길이는 배열이름.length 이다.
*문자열의 길이를 구할 때는 str.length()를 사용한다. length는 메서드가 아니라 필드라서, 배열은 length뒤에 ()를 안 붙이고, 문자열은 붙여야 한다.
*Java에서 길이를 구하는 대표적인 메소드는 .length와 .length(), .size()가 있다. .length는 배열의 길이를 확인할 때 사용되고, .length()는 문자열의 길이를, .size는 Collections Framework의 ArrayList의 길이를 확인할 때 사용한다.
배열의 출력
프로그래밍 도중 내가 만든 배열의 상태를 보기 위해 콘솔에 배열 내용물을 출력하고 싶을 때 아래처럼 System.out.println(score)으로 배열 변수를 출력해보면 이상한 값이 출력되게 된다.
int[] score = {100, 90, 80, 70, 60};
System.out.println(score); // [I@14318bb]
이 이상한 값은 메모리에 있는 배열의 주소값(타입@주소)을 가리키는 것이다.
따라서 for문을 이용해서 배열 각 원소들을 순회하여 출력하도록 하드코딩 해주거나, 아니면 자바에서 제공해주는 Arrays.toString() 메서드를 이용해서 배열을 문자열 형식으로 만들어 출력할 수도 있다.
int[] score = {100, 90, 80, 70, 60};
// 방법1
for(int i = 0; i < score.length; i++){ // 배열의 요소를 순서대로 하나씩 출력
System.out.println(score[i]);
}
// 방법2
System.out.println(Arrays.toString(score)); // "[100, 90, 80, 70, 60]"
int[] 활용
class Ex5_2 {
public static void main(String[] args) {
int sum = 0; // 총합을 저장하기 위한 변수
float average = 0f; // 평균을 저장하기 위한 변수
int[] score = {100, 88, 100, 100, 90}; // 점수를 저장하는 배열
for (int i = 0; i < score.length; i++) {
sum += score[i]; // 배열의 모든 요소를 더함
}
average = sum / (float)score.length; // 계산 결과를 float 타입으로 변환하여 저장
System.out.println("총합 : " + sum);
System.out.println("평균 : " + average);
}
}
class Ex5_3 {
public static void main(String[] args) {
int[] score = {79, 88, 91, 33, 100, 55, 95};
int max = score[0]; // 배열의 첫 번째 값으로 최댓값을 초기화
int min = score[0]; // 배열의 첫 번째 값으로 최솟값을 초기화
for (int i = 1; i < score.length; i++) { // 두 번째 요소부터 비교
if (score[i] > max) {
max = score[i]; // 최댓값 갱신
} else if (score[i] < min) {
min = score[i]; // 최솟값 갱신
}
}
System.out.println("최대값 : " + max);
System.out.println("최소값 : " + min);
}
}
import java.util.Arrays;
class Ex5_4 {
public static void main(String[] args) {
int[] numArr = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; // 초기 배열
System.out.println(Arrays.toString(numArr)); // 원래 배열 출력
for (int i = 0; i < 100; i++) { // 100번 섞기 반복
int n = (int) (Math.random() * 10); // 0~9 사이의 랜덤한 인덱스 선택
// numArr[0]과 numArr[n]의 값 교환 (Shuffle)
int tmp = numArr[0];
numArr[0] = numArr[n];
numArr[n] = tmp;
}
System.out.println(Arrays.toString(numArr)); // 섞인 배열 출력
}
}
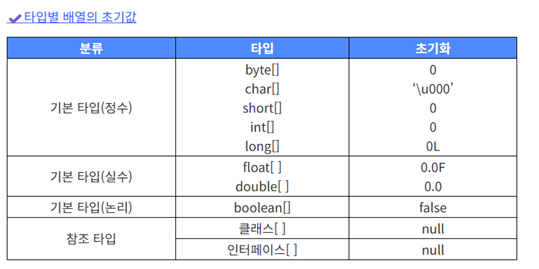
타입별 배열의 초기값
객체 배열
자바에서는 동일 타입의 여러객체를 생성하여 사용할때는 객체 배열을 사용한다.
Book 객체 3개를 배열 형태로 만들어 사용하기 위해서 먼저 아래와 같이 코드를 작성하게 되면, 레퍼런스 변수 b와 Book 객체에 대한 레퍼런스 변수 3개가 생성된다.
Book[] b = new Book[3];
이렇게 선언하게 되면 Book 객체를 담을 레퍼런스 변수 3개가 배열형태로 생성된다. 주의할 점은 아직 Book 객체가 만들어진것은 아니기 때문에, Book 객체를 사용하기 위해서는 아래와 같이 Book 객체를 생성해 주어야 한다.
b[0] = new Book();
b[1] = new Book();
b[2] = new Book();
// 혹은
// Book[] b = { new Book(), new Book(), new Book() };
//1) Book 객체에 대한 클래스 정의
public class Book {
String title;
int price;
public Book() { } // 생성자
public void showPrice() {
System.out.println(title + "의 가격은 " + price + "원 입니다");
}
}
//2) Book 객체 배열 생성 및 사용
public class HelloWorld {
public static void main(String[] args) {
Book[] b = new Book[3]; // 객체 배열 선언 및 생성
for (int i=0; i<b.length; i++) {
b[i] = new Book(); // Book 객체 생성
}
b[0].title = "국어책";
b[0].price = 3000;
b[1].title = "영어책";
b[1].price = 4000;
b[2].title = "수학책";
b[2].price = 5000;
for (int i=0; i<b.length; i++) {
b[i].showPrice();
}
}
}
//3) 실행결과
//국어책의 가격은 3000원 입니다
//영어책의 가격은 4000원 입니다
//수학책의 가격은 5000원 입니다
String 배열
// String 배열 선언과 초기화
String[] name = new String[3];
name[0] = "Kim"
name[1] = "Park"
name[2] = "Yi"
// 처음부터 선언+초기화를 한번에 진행
String[] name2 = {"Kim", "Park", "Yi"};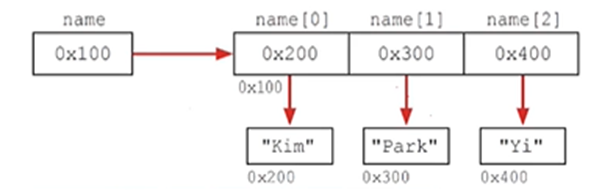
// 가위바위보중에 하나가 나오도록 하는 프로그램 예제
import java.util.Arrays;
class Ex5_1_tmp {
public static void main(String[] args) {
// index: 0~3-1, 즉 0~2
String[] strArr = { "가위", "바위", "보" };
System.out.println(Arrays.toString(strArr)); // 배열 출력
for (int i = 0; i < 10; i++) {
int tmp = (int) (Math.random() * 3); // 0~2 사이의 랜덤 숫자 생성
System.out.println(strArr[tmp]); // 랜덤으로 가위, 바위, 보 중 하나 출력
}
}
}
2차원 배열
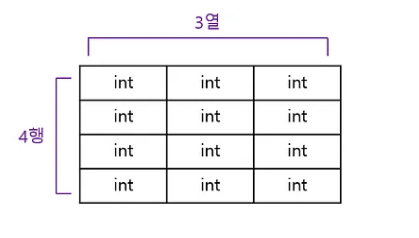
2차원 배열이란, 테이블 형테의 데이터를 저장하기 위한 배열이다. 테이블 형태의 데이터란 아래와 같은 데이터를 말한다.
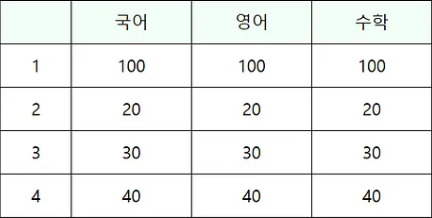
위의 표는 4행 3열의 int 값을 가지고 있다. 이러한 2차원 배열이 여러 층이면 3차원 배열이 된다. 참고로 여기서 1행씩 떼어서 보면 지금까지 많이 보던 1차원 배열이 된다.
2차원 배열을 선언하는 방법은 1차원 배열과 같지만, 괄호[ ]가 하나 더 들어간다.
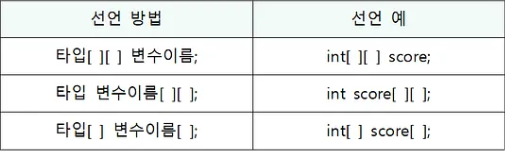
int[][] score = new int[4][3]; // 4행 3열의 2차원 배열 생성위의 식으로 2차원 배열을 생성하면 아래와 같은 배열의 저장공간을 생성하게 된다.
2차원 배열의 인덱스
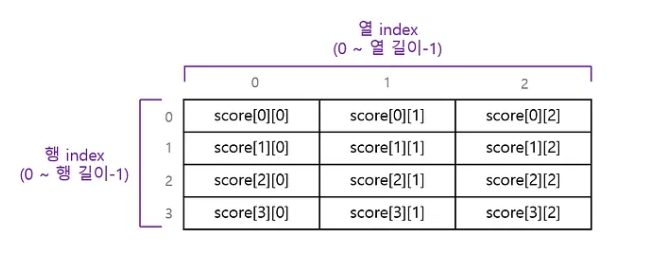
2차원 배열은 행(row)과 열(column)로 구성되어 있기 때문에 index도 행과 열에 각각 하나씩 존재한다.
‘행index’의 범위는 ‘0~(행길이-1)’이고, ‘열index’의 범위는 ‘0~(열길이-1)’이다. 이를 ‘배열이름[행index][열index]’로 표현한다.
int[][] score = new int[4][3];위와 같이 배열 score를 생성하면, score[0][0]부터 score[3][2]까지 모두 12개의 int값을 저장할 수 있는 공간이 마련된다. 아래 그림으로 이해하면 쉽다.
배열 score의 1행 1열에 100을 저장하고, 이 값을 출력하려면 다음과 같이 할 수 있다.
score[0][0] = 100; // 배열 score의 1행 1열에 100을 저장
System.out.println(score[0][0]); // 배열 score의 1행 1열의 값을 출력
2차원 배열의 초기화
2차원 배열의 초기화는 괄호{ }를 사용해서 생성과 초기화를 동시에 할 수 있다. 1차원 배열보다 괄호를 한번 더 써서 행별로 구분한다.

①번 보다는 ②번을 많이 쓴다. 크기가 작은 배열은 ②번처럼 간단하게 한 줄로 쓰면 편하지만, 가능하다면 ③번처럼 행 별로 줄 바꿈을 하는 것이 이해하기 쉽다.
예를 들어, 아래와 같은 테이블 형태의 데이터를 배열에 저장해보자.
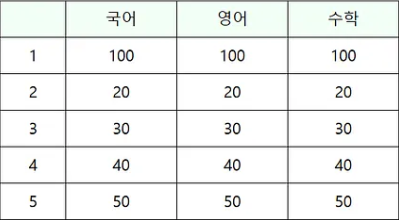
생성과 초기화는 아래와 같이 하면 된다.
int[][] score = {
{100, 100, 100},
{20, 20, 20},
{30, 30, 30},
{40, 40, 40},
{50, 50, 50},
};이때 2차원 배열 score가 메모리에 어떤 형태로 저장되는지 그려보면 아래와 같다.
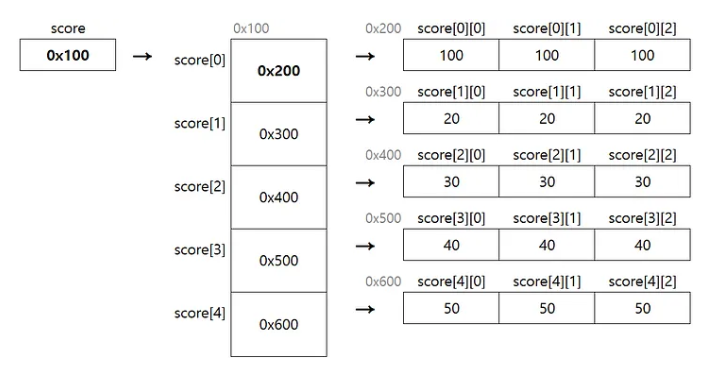
그림을 보면, 2차원 배열은 여러 개의 1차원 배열을 묶어서 하나의 배열로 만든 것이다. 다시 말해 ‘배열의 배열’이라고 표현할 수 있다.
2차원 배열의 길이
또한 2차원 배열에서는 1차원 배열과 같이 .length로 행과 열의 길이를 알 수 있다.
변수명.length는 배열의 행 수를 의미하고, 변수명[0].length는 배열의 0번째 행의 총 길이를 구하게 된다.
public class Exam{
public static void main(String[] args){
int[][] array = new int[6][7];
System.out.println(array.length);
System.out.println(array[0].length);
}
}
2차원 배열 예제
//2차원 배열 관련된 예제
class Ex5_8 {
public static void main(String[] args) {
int[][] score = {
{100, 100, 100},
{20, 20, 20},
{30, 30, 30},
{40, 40, 40}
};
int sum = 0;
for (int i=0; i<score.length; i++) {
for (int j=0; j<score[i].length; j++) {
System.out.printf("score[%d][%d] = %d%n", i, j, score[i][j]);
sum += score[i][j];
}
}
System.out.println("sum = "+sum);
}
}
import java.util.Scanner;
public class practice {
public static void main(String[] args) {
String[][] Quiz= {
{"computer", "컴퓨터"},
{"chair", "의자"},
{"integer","정수"}
}; // string 3*2 two dimensional array
Scanner scanner= new Scanner(System.in);
for(int i=0; i< Quiz.length; i++) {
System.out.printf("Q%d. %s의 뜻은? ", i+1, Quiz[i][0]);
String answer=scanner.nextLine();
if(answer.equals(Quiz[i][1])) {
System.out.println("정답입니다.");
}
else {
System.out.println("틀렸습니다. 정답은"+Quiz[i][1]+"입니다");
}
}
}
}
// Q. Chair의 뜻은? 의자
// 정답입니다.
// Q. computer의 뜻은?ㅁㄴㅇㄹ
// 틀렸습니다. 정답은 컴퓨터입니다.
// Q. Integer의 뜻은?정수
// 정답입니다.
Arrays 클래스
java.util 패키지의 일부로, 배열을 다루기 위한 다양한 메서드를 제공한다.
Arrays.toString()
배열을 문자열로 변환하여 출력하는 메서드, 1차원 배열만 지원하며, 다차원 배열은 Arrays.deepToString()을 사용해야한다.
int[] arr = {1, 2, 3, 4, 5};
System.out.println(Arrays.toString(arr));
// 출력: [1, 2, 3, 4, 5]
Arrays.copyOf()
배열을 원하는 길이만큼 복사하여 새로운 배열을 생성한다.
int[] original = {1, 2, 3};
int[] copy = Arrays.copyOf(original, 5);
System.out.println(Arrays.toString(copy));
// 출력: [1, 2, 3, 0, 0] (빈 공간은 0으로 채워짐)
Arrays.copyOfRange()
배열의 특정 범위만 복사하여 새로운 배열을 생성한다. toIndex는 포함되지 않음.
int[] original = {10, 20, 30, 40, 50};
int[] copy = Arrays.copyOfRange(original, 1, 4);
System.out.println(Arrays.toString(copy));
// 출력: [20, 30, 40]
Arrays.fill()
배열의 모든 요소를 특정 값으로 채운다.
int[] arr = new int[5];
Arrays.fill(arr, 7);
System.out.println(Arrays.toString(arr));
// 출력: [7, 7, 7, 7, 7]
Arrays.setAll()
배열의 각 요소를 람다 표현식을 이용해 초기화할 수 있다.
int[] arr = new int[5];
Arrays.setAll(arr, i -> i * 2); // 인덱스 값의 2배를 저장
System.out.println(Arrays.toString(arr));
// 출력: [0, 2, 4, 6, 8]
Arrays.sort()
배열을 오름차순으로 정렬한다. 기본형 배열과 객체 배열 모두 정렬 가능.
int[] arr = {5, 3, 8, 1, 2};
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
// 출력: [1, 2, 3, 5, 8]
내림차순 정렬할 때는 Collections.reverseOrder() 메서드를 사용한다. sort()에 Collections.reverseOrder()를 인자로 전달하려면 배열은 Primitive Type 배열이 아닌 Integer, String 같은 Wrapper 클래스를 사용해야한다.
import java.util.Arrays;
import java.util.Collections;
public class Example2 {
public static void main(String[] args) {
Integer[] numbers = {5, 3, 8, 1, 2, 7};
// 배열 정렬
Arrays.sort(numbers, Collections.reverseOrder());
// 정렬된 배열 출력
System.out.println("Sorted array: " + Arrays.toString(numbers));
}
}
// 출력
// Sorted array: [8, 7, 5, 3, 2, 1]
Arrays.binarySearch()
이진 탐색을 수행하여 특정 요소의 인덱스를 반환한다. 반드시 Arrays.sort()로 정렬된 배열에서 사용해야 한다.
int[] arr = {1, 3, 5, 7, 9};
int index = Arrays.binarySearch(arr, 5);
System.out.println(index);
// 출력: 2 (5의 위치)
Arrays.deepToString()
다차원 배열을 문자열로 변환한다.
int[][] arr = {{1, 2}, {3, 4}};
System.out.println(Arrays.deepToString(arr));
// 출력: [[1, 2], [3, 4]]
Arrays.deepEquals()
다차원 배열의 내용이 동일한지 비교한다. (Arrays.equals()는 1차원 배열만 비교 가능)
int[][] arr1 = {{1, 2}, {3, 4}};
int[][] arr2 = {{1, 2}, {3, 4}};
System.out.println(Arrays.deepEquals(arr1, arr2));
// 출력: true
Arrays.asList()
배열을 고정 크기 리스트로 변환한다. 이 리스트는 크기 변경 불가능 (add/remove 불가)
List<String> list = Arrays.asList("A", "B", "C");
System.out.println(list);
// 출력: [A, B, C]
Arrays.equals()
두 배열의 요소가 모두 동일한지 비교한다.
int[] arr1 = {1, 2, 3};
int[] arr2 = {1, 2, 3};
System.out.println(Arrays.equals(arr1, arr2));
// 출력: true
배열 시간복잡도
삽입/삭제
- 배열의 맨 앞에 삽입/삭제: O(n)
- 배열의 맨 뒤에 삽입/삭제: O(1)
- 배열의 중간에 삽입/삭제: O(n)
탐색
- O(1)
※ 위와 같이 시간 복잡도가 되는 이유는 배열의 원소가 키(혹은 인덱스)와 값(value)로 이루어져 있기 때문.
※ 인덱스가 i인 원소에 접근
우리가 배열의 첫 번째 원소의 주소를 알고 있으니 i번째 원소에 접근하기 위해서는 첫 번째 원소의 주소 + (자료형 크기) * i 한 주소에 접근하면 된다. 따라서 시간 복잡도는 O(1)
'🧠 Computer Science > Data Structure' 카테고리의 다른 글
| [선형 데이터 구조] 배열리스트(ArrayList) (0) | 2025.03.24 |
|---|
개요
배열(Array)은 컴퓨터 과학에서 가장 기본적이고 널리 사용되는 선형 데이터 구조이다. 데이터 구조가 선형이라는 것은 데이터 구조를 구성하는 요소들이 서로 인접해 순차적인 방식으로 정렬되어 있음을 뜻한다.
이 구조는 데이터를 순차적으로 저장하고 접근하는 방식을 제공하며, 많은 알고리즘과 프로그램의 기반이 된다.
배열은 동일한 데이터 타입의 요소들을 연속된 메모리 공간에 저장하는 자료구조이다. 배열의 주요 특징은 다음과 같다.
- 고정된 크기: 배열은 생성 시 크기가 정해지며, 이후 변경이 어렵다.
- 인덱스 기반 접근: 각 요소는 0부터 시작하는 인덱스를 통해 직접 접근할 수 있다.
- 빠른 접근 속도: 인덱스를 통한 요소 접근은 O(1)의 시간 복잡도를 가진다.
- 메모리 효율성: 연속된 메모리 공간을 사용하여 메모리 관리가 효율적이다.
- 다차원 구조 가능: 2차원, 3차원 등의 다차원 배열 구현이 가능하다.
배열의 이러한 특성은 특정 상황에서 큰 장점이 된다. 예를 들어, 데이터의 크기가 미리 알려져 있고 변하지 않는 경우, 또는 빠른 랜덤 접근이 필요한 경우에 배열은 매우 효과적이다. 그러나 배열의 크기를 변경하기 어렵다는 점은 동적인 데이터 처리에 제한이 될 수 있다. 그래서 데이터의 크기가 자주 변하거나, 중간에 요소를 자주 삽입/삭제해야 하는 경우에 리스트 자료구조를 사용한다.
배열은 다양한 알고리즘과 응용 프로그램에서 중요한 역할을 한다. 예를 들어, 배열은 정렬 알고리즘, 행렬 연산, 해시 테이블의 구현 등에 널리 사용된다.
프로그래밍 언어에 따라 배열의 구현과 사용 방법이 다를 수 있다. 예를 들어, C언어에서는 정적 배열과 동적 할당을 통한 배열 사용이 일반적이며, 연결 리스트는 개발자가 직접 구현해야 한다. 반면 Java나 Python과 같은 고수준 언어에서는 동적 배열(ArrayList)과 연결 리스트(LinkedList)를 기본 라이브러리로 제공한다.
배열과 리스트를 효과적으로 사용하기 위해서는 각 구조의 특성을 잘 이해하고, 문제의 요구사항에 맞게 적절한 구조를 선택해야 한다. 예를 들어, 데이터의 크기가 고정되어 있고 빈번한 검색이 필요한 경우에는 배열이 적합할 수 있다. 반면, 데이터의 삽입과 삭제가 빈번하게 일어나는 경우에는 연결 리스트가 더 효율적일 수 있다.
또한, 배열과 리스트는 더 복잡한 자료구조의 기반이 되기도 한다. 예를 들어, 스택과 큐는 배열이나 연결 리스트를 사용하여 구현할 수 있으며, 그래프의 인접 행렬 표현은 2차원 배열을, 인접 리스트 표현은 리스트의 배열을 사용한다.
배열의 선언&초기화
배열이란 "배열은 같은 타입의 여러 변수를 하나의 묶음으로 다루는 것"이다.
변수는 1개의 데이터만 저장할 수 있다. 저장해야 할 데이터의 수가 많아지면 그만큼 많은 변수가 필요하고 아래처럼 코드도 매우 길어진다. 하지만 배열을 사용하면 많은 양의 데이터를 적은 코드로 손쉽게 처리할 수 있다.
int score1 = 83;
int score2 = 90;
int score3 = 87;
int score4 = 75;
배열 선언 후 초기화
int[] score = new int[5];
score[0] = 100;
score[1] = 90;
score[2] = 80;
score[3] = 70;
score[4] = 60;
배열 선언 후 for문으로 초기화
int[] score = new int[5];
for(int i = 0; i < score.length; i++){
score[i] = i * 10;
}
배열 선언과 동시에 초기화
int[] score = new int[]{100, 90, 80, 70, 60};
//선언과 동시에 값을 초기화할 때는 new int[] 부분을 생략할 수도 있다.
int[] score2 = {100, 90, 80, 70, 60};
배열의 길이
배열은 한번 생성하면 길이를 변경할 수 없다.
그 이유는 예를 들어 int[] arr = new int[5]; 라고 하면 하나의 요소가 4byte를 차지하니 총 20byte이다. 이럴 경우 배열은 연속적이기 때문에 메모리에서 20byte인 연속적인 메모리 공간을 확보해야한다. 하지만 int[] arr = new int[10]로 변경하고 싶다면 총 연속적인 40byte인 메모리 공간이 필요하다. 이때, 처음에 연속적인 20byte 메모리 공간 뒤가 비어있다는 보장이 없다. 그래서 변경할 수 없는것이다.
공간이 부족하다면 새로운 더 큰 공간을 만들고 기존의 배열의 요소들을 복사해야한다. 배열의 길이는 배열이름.length 이다.
*문자열의 길이를 구할 때는 str.length()를 사용한다. length는 메서드가 아니라 필드라서, 배열은 length뒤에 ()를 안 붙이고, 문자열은 붙여야 한다.
*Java에서 길이를 구하는 대표적인 메소드는 .length와 .length(), .size()가 있다. .length는 배열의 길이를 확인할 때 사용되고, .length()는 문자열의 길이를, .size는 Collections Framework의 ArrayList의 길이를 확인할 때 사용한다.
배열의 출력
프로그래밍 도중 내가 만든 배열의 상태를 보기 위해 콘솔에 배열 내용물을 출력하고 싶을 때 아래처럼 System.out.println(score)으로 배열 변수를 출력해보면 이상한 값이 출력되게 된다.
int[] score = {100, 90, 80, 70, 60};
System.out.println(score); // [I@14318bb]
이 이상한 값은 메모리에 있는 배열의 주소값(타입@주소)을 가리키는 것이다.
따라서 for문을 이용해서 배열 각 원소들을 순회하여 출력하도록 하드코딩 해주거나, 아니면 자바에서 제공해주는 Arrays.toString() 메서드를 이용해서 배열을 문자열 형식으로 만들어 출력할 수도 있다.
int[] score = {100, 90, 80, 70, 60};
// 방법1
for(int i = 0; i < score.length; i++){ // 배열의 요소를 순서대로 하나씩 출력
System.out.println(score[i]);
}
// 방법2
System.out.println(Arrays.toString(score)); // "[100, 90, 80, 70, 60]"
int[] 활용
class Ex5_2 {
public static void main(String[] args) {
int sum = 0; // 총합을 저장하기 위한 변수
float average = 0f; // 평균을 저장하기 위한 변수
int[] score = {100, 88, 100, 100, 90}; // 점수를 저장하는 배열
for (int i = 0; i < score.length; i++) {
sum += score[i]; // 배열의 모든 요소를 더함
}
average = sum / (float)score.length; // 계산 결과를 float 타입으로 변환하여 저장
System.out.println("총합 : " + sum);
System.out.println("평균 : " + average);
}
}
class Ex5_3 {
public static void main(String[] args) {
int[] score = {79, 88, 91, 33, 100, 55, 95};
int max = score[0]; // 배열의 첫 번째 값으로 최댓값을 초기화
int min = score[0]; // 배열의 첫 번째 값으로 최솟값을 초기화
for (int i = 1; i < score.length; i++) { // 두 번째 요소부터 비교
if (score[i] > max) {
max = score[i]; // 최댓값 갱신
} else if (score[i] < min) {
min = score[i]; // 최솟값 갱신
}
}
System.out.println("최대값 : " + max);
System.out.println("최소값 : " + min);
}
}
import java.util.Arrays;
class Ex5_4 {
public static void main(String[] args) {
int[] numArr = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; // 초기 배열
System.out.println(Arrays.toString(numArr)); // 원래 배열 출력
for (int i = 0; i < 100; i++) { // 100번 섞기 반복
int n = (int) (Math.random() * 10); // 0~9 사이의 랜덤한 인덱스 선택
// numArr[0]과 numArr[n]의 값 교환 (Shuffle)
int tmp = numArr[0];
numArr[0] = numArr[n];
numArr[n] = tmp;
}
System.out.println(Arrays.toString(numArr)); // 섞인 배열 출력
}
}
타입별 배열의 초기값
객체 배열
자바에서는 동일 타입의 여러객체를 생성하여 사용할때는 객체 배열을 사용한다.
Book 객체 3개를 배열 형태로 만들어 사용하기 위해서 먼저 아래와 같이 코드를 작성하게 되면, 레퍼런스 변수 b와 Book 객체에 대한 레퍼런스 변수 3개가 생성된다.
Book[] b = new Book[3];
이렇게 선언하게 되면 Book 객체를 담을 레퍼런스 변수 3개가 배열형태로 생성된다. 주의할 점은 아직 Book 객체가 만들어진것은 아니기 때문에, Book 객체를 사용하기 위해서는 아래와 같이 Book 객체를 생성해 주어야 한다.
b[0] = new Book();
b[1] = new Book();
b[2] = new Book();
// 혹은
// Book[] b = { new Book(), new Book(), new Book() };
//1) Book 객체에 대한 클래스 정의
public class Book {
String title;
int price;
public Book() { } // 생성자
public void showPrice() {
System.out.println(title + "의 가격은 " + price + "원 입니다");
}
}
//2) Book 객체 배열 생성 및 사용
public class HelloWorld {
public static void main(String[] args) {
Book[] b = new Book[3]; // 객체 배열 선언 및 생성
for (int i=0; i<b.length; i++) {
b[i] = new Book(); // Book 객체 생성
}
b[0].title = "국어책";
b[0].price = 3000;
b[1].title = "영어책";
b[1].price = 4000;
b[2].title = "수학책";
b[2].price = 5000;
for (int i=0; i<b.length; i++) {
b[i].showPrice();
}
}
}
//3) 실행결과
//국어책의 가격은 3000원 입니다
//영어책의 가격은 4000원 입니다
//수학책의 가격은 5000원 입니다
String 배열
// String 배열 선언과 초기화
String[] name = new String[3];
name[0] = "Kim"
name[1] = "Park"
name[2] = "Yi"
// 처음부터 선언+초기화를 한번에 진행
String[] name2 = {"Kim", "Park", "Yi"};// 가위바위보중에 하나가 나오도록 하는 프로그램 예제
import java.util.Arrays;
class Ex5_1_tmp {
public static void main(String[] args) {
// index: 0~3-1, 즉 0~2
String[] strArr = { "가위", "바위", "보" };
System.out.println(Arrays.toString(strArr)); // 배열 출력
for (int i = 0; i < 10; i++) {
int tmp = (int) (Math.random() * 3); // 0~2 사이의 랜덤 숫자 생성
System.out.println(strArr[tmp]); // 랜덤으로 가위, 바위, 보 중 하나 출력
}
}
}
2차원 배열
2차원 배열이란, 테이블 형테의 데이터를 저장하기 위한 배열이다. 테이블 형태의 데이터란 아래와 같은 데이터를 말한다.
위의 표는 4행 3열의 int 값을 가지고 있다. 이러한 2차원 배열이 여러 층이면 3차원 배열이 된다. 참고로 여기서 1행씩 떼어서 보면 지금까지 많이 보던 1차원 배열이 된다.
2차원 배열을 선언하는 방법은 1차원 배열과 같지만, 괄호[ ]가 하나 더 들어간다.
int[][] score = new int[4][3]; // 4행 3열의 2차원 배열 생성위의 식으로 2차원 배열을 생성하면 아래와 같은 배열의 저장공간을 생성하게 된다.
2차원 배열의 인덱스
2차원 배열은 행(row)과 열(column)로 구성되어 있기 때문에 index도 행과 열에 각각 하나씩 존재한다.
‘행index’의 범위는 ‘0~(행길이-1)’이고, ‘열index’의 범위는 ‘0~(열길이-1)’이다. 이를 ‘배열이름[행index][열index]’로 표현한다.
int[][] score = new int[4][3];위와 같이 배열 score를 생성하면, score[0][0]부터 score[3][2]까지 모두 12개의 int값을 저장할 수 있는 공간이 마련된다. 아래 그림으로 이해하면 쉽다.
배열 score의 1행 1열에 100을 저장하고, 이 값을 출력하려면 다음과 같이 할 수 있다.
score[0][0] = 100; // 배열 score의 1행 1열에 100을 저장
System.out.println(score[0][0]); // 배열 score의 1행 1열의 값을 출력
2차원 배열의 초기화
2차원 배열의 초기화는 괄호{ }를 사용해서 생성과 초기화를 동시에 할 수 있다. 1차원 배열보다 괄호를 한번 더 써서 행별로 구분한다.
①번 보다는 ②번을 많이 쓴다. 크기가 작은 배열은 ②번처럼 간단하게 한 줄로 쓰면 편하지만, 가능하다면 ③번처럼 행 별로 줄 바꿈을 하는 것이 이해하기 쉽다.
예를 들어, 아래와 같은 테이블 형태의 데이터를 배열에 저장해보자.
생성과 초기화는 아래와 같이 하면 된다.
int[][] score = {
{100, 100, 100},
{20, 20, 20},
{30, 30, 30},
{40, 40, 40},
{50, 50, 50},
};이때 2차원 배열 score가 메모리에 어떤 형태로 저장되는지 그려보면 아래와 같다.
그림을 보면, 2차원 배열은 여러 개의 1차원 배열을 묶어서 하나의 배열로 만든 것이다. 다시 말해 ‘배열의 배열’이라고 표현할 수 있다.
2차원 배열의 길이
또한 2차원 배열에서는 1차원 배열과 같이 .length로 행과 열의 길이를 알 수 있다.
변수명.length는 배열의 행 수를 의미하고, 변수명[0].length는 배열의 0번째 행의 총 길이를 구하게 된다.
public class Exam{
public static void main(String[] args){
int[][] array = new int[6][7];
System.out.println(array.length);
System.out.println(array[0].length);
}
}
2차원 배열 예제
//2차원 배열 관련된 예제
class Ex5_8 {
public static void main(String[] args) {
int[][] score = {
{100, 100, 100},
{20, 20, 20},
{30, 30, 30},
{40, 40, 40}
};
int sum = 0;
for (int i=0; i<score.length; i++) {
for (int j=0; j<score[i].length; j++) {
System.out.printf("score[%d][%d] = %d%n", i, j, score[i][j]);
sum += score[i][j];
}
}
System.out.println("sum = "+sum);
}
}
import java.util.Scanner;
public class practice {
public static void main(String[] args) {
String[][] Quiz= {
{"computer", "컴퓨터"},
{"chair", "의자"},
{"integer","정수"}
}; // string 3*2 two dimensional array
Scanner scanner= new Scanner(System.in);
for(int i=0; i< Quiz.length; i++) {
System.out.printf("Q%d. %s의 뜻은? ", i+1, Quiz[i][0]);
String answer=scanner.nextLine();
if(answer.equals(Quiz[i][1])) {
System.out.println("정답입니다.");
}
else {
System.out.println("틀렸습니다. 정답은"+Quiz[i][1]+"입니다");
}
}
}
}
// Q. Chair의 뜻은? 의자
// 정답입니다.
// Q. computer의 뜻은?ㅁㄴㅇㄹ
// 틀렸습니다. 정답은 컴퓨터입니다.
// Q. Integer의 뜻은?정수
// 정답입니다.
Arrays 클래스
java.util 패키지의 일부로, 배열을 다루기 위한 다양한 메서드를 제공한다.
Arrays.toString()
배열을 문자열로 변환하여 출력하는 메서드, 1차원 배열만 지원하며, 다차원 배열은 Arrays.deepToString()을 사용해야한다.
int[] arr = {1, 2, 3, 4, 5};
System.out.println(Arrays.toString(arr));
// 출력: [1, 2, 3, 4, 5]
Arrays.copyOf()
배열을 원하는 길이만큼 복사하여 새로운 배열을 생성한다.
int[] original = {1, 2, 3};
int[] copy = Arrays.copyOf(original, 5);
System.out.println(Arrays.toString(copy));
// 출력: [1, 2, 3, 0, 0] (빈 공간은 0으로 채워짐)
Arrays.copyOfRange()
배열의 특정 범위만 복사하여 새로운 배열을 생성한다. toIndex는 포함되지 않음.
int[] original = {10, 20, 30, 40, 50};
int[] copy = Arrays.copyOfRange(original, 1, 4);
System.out.println(Arrays.toString(copy));
// 출력: [20, 30, 40]
Arrays.fill()
배열의 모든 요소를 특정 값으로 채운다.
int[] arr = new int[5];
Arrays.fill(arr, 7);
System.out.println(Arrays.toString(arr));
// 출력: [7, 7, 7, 7, 7]
Arrays.setAll()
배열의 각 요소를 람다 표현식을 이용해 초기화할 수 있다.
int[] arr = new int[5];
Arrays.setAll(arr, i -> i * 2); // 인덱스 값의 2배를 저장
System.out.println(Arrays.toString(arr));
// 출력: [0, 2, 4, 6, 8]
Arrays.sort()
배열을 오름차순으로 정렬한다. 기본형 배열과 객체 배열 모두 정렬 가능.
int[] arr = {5, 3, 8, 1, 2};
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
// 출력: [1, 2, 3, 5, 8]
내림차순 정렬할 때는 Collections.reverseOrder() 메서드를 사용한다. sort()에 Collections.reverseOrder()를 인자로 전달하려면 배열은 Primitive Type 배열이 아닌 Integer, String 같은 Wrapper 클래스를 사용해야한다.
import java.util.Arrays;
import java.util.Collections;
public class Example2 {
public static void main(String[] args) {
Integer[] numbers = {5, 3, 8, 1, 2, 7};
// 배열 정렬
Arrays.sort(numbers, Collections.reverseOrder());
// 정렬된 배열 출력
System.out.println("Sorted array: " + Arrays.toString(numbers));
}
}
// 출력
// Sorted array: [8, 7, 5, 3, 2, 1]
Arrays.binarySearch()
이진 탐색을 수행하여 특정 요소의 인덱스를 반환한다. 반드시 Arrays.sort()로 정렬된 배열에서 사용해야 한다.
int[] arr = {1, 3, 5, 7, 9};
int index = Arrays.binarySearch(arr, 5);
System.out.println(index);
// 출력: 2 (5의 위치)
Arrays.deepToString()
다차원 배열을 문자열로 변환한다.
int[][] arr = {{1, 2}, {3, 4}};
System.out.println(Arrays.deepToString(arr));
// 출력: [[1, 2], [3, 4]]
Arrays.deepEquals()
다차원 배열의 내용이 동일한지 비교한다. (Arrays.equals()는 1차원 배열만 비교 가능)
int[][] arr1 = {{1, 2}, {3, 4}};
int[][] arr2 = {{1, 2}, {3, 4}};
System.out.println(Arrays.deepEquals(arr1, arr2));
// 출력: true
Arrays.asList()
배열을 고정 크기 리스트로 변환한다. 이 리스트는 크기 변경 불가능 (add/remove 불가)
List<String> list = Arrays.asList("A", "B", "C");
System.out.println(list);
// 출력: [A, B, C]
Arrays.equals()
두 배열의 요소가 모두 동일한지 비교한다.
int[] arr1 = {1, 2, 3};
int[] arr2 = {1, 2, 3};
System.out.println(Arrays.equals(arr1, arr2));
// 출력: true
배열 시간복잡도
삽입/삭제
- 배열의 맨 앞에 삽입/삭제: O(n)
- 배열의 맨 뒤에 삽입/삭제: O(1)
- 배열의 중간에 삽입/삭제: O(n)
탐색
- O(1)
※ 위와 같이 시간 복잡도가 되는 이유는 배열의 원소가 키(혹은 인덱스)와 값(value)로 이루어져 있기 때문.
※ 인덱스가 i인 원소에 접근
우리가 배열의 첫 번째 원소의 주소를 알고 있으니 i번째 원소에 접근하기 위해서는 첫 번째 원소의 주소 + (자료형 크기) * i 한 주소에 접근하면 된다. 따라서 시간 복잡도는 O(1)
'🧠 Computer Science > Data Structure' 카테고리의 다른 글
| [선형 데이터 구조] 배열리스트(ArrayList) (0) | 2025.03.24 |
|---|